簡單測試使用 WhisperDesktop 將語音轉成文字
TLDR
- WhisperDesktop 是一款無需 Python 環境即可運行的 OpenAI Whisper 離線語音轉文字工具。
- 建議優先使用
ggml-medium.bin模型,在效能與準確度間取得最佳平衡。 - 擁有獨立顯示卡者,使用
ggml-medium.bin處理 5 分鐘音訊僅需約 11 秒。 - 無獨立顯示卡者,建議選用
ggml-small.bin作為日常使用基準,ggml-tiny.bin準確率過低。 - 開發者已停止更新 WhisperDesktop,建議改用 Subtitle Edit 整合 Faster-Whisper 以獲得更佳的效能與維護支援。
WARNING
WhisperDesktop 開發者已許久未更新。目前建議改用 Subtitle Edit 整合 Faster-Whisper,維護相對活躍且速度更快。詳細請參考:使用 Subtitle Edit 整合 Faster-Whisper 進行本地語音轉文字。
下載與安裝
WhisperDesktop 是一個輕量化的離線工具,無需安裝 Python 環境。
- 前往 WhisperDesktop GitHub 的 Releases 頁面下載最新版本。
- 解壓縮後包含
WhisperDesktop.exe(執行檔)與Whisper.dll(函式庫)。
模型選擇與規格
模型需從 Huggingface Whisper 下載。模型大小直接影響 VRAM 需求與處理速度:
| 大小 | 參數數量 | 需求 VRAM | 相對速度 |
|---|---|---|---|
| tiny | 39 M | ~1 GB | ~32x |
| base | 74 M | ~1 GB | ~16x |
| small | 244 M | ~2 GB | ~6x |
| medium | 769 M | ~5 GB | ~2x |
| large | 1550 M | ~10 GB | 1x |
使用方法
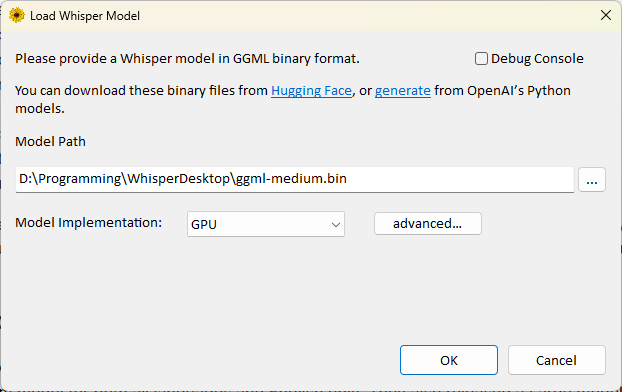
什麼情況下會遇到設定問題:當軟體無法自動偵測硬體時,需手動調整參數。
- 執行
WhisperDesktop.exe並指定模型路徑。 - Model Implementation 選擇
GPU。若無法偵測顯卡,可點擊advanced...進行手動設定。 - Language 選擇目標語言。
- Output Format 支援
.txt、.srt、.vtt等多種格式。 - 勾選
Place that file to the input folder可將輸出檔案直接存於輸入檔案目錄。
效能測試結果
什麼情況下會遇到效能瓶頸:使用過大的模型(如 large)在特定硬體上可能導致處理失敗或輸出空白。
- 獨立顯示卡 (RTX 4070 Ti Super):
ggml-medium.bin:處理 5 分 16 秒音訊僅需 11 秒。ggml-large-v3.bin:處理時間長達 22 分鐘,且存在轉換失敗風險。
- 內顯 (i7-12700H):
ggml-tiny.bin:41 秒。ggml-small.bin:4 分 19 秒。ggml-medium.bin:13 分 5 秒。
結論與建議
- 獨立顯卡使用者:建議統一使用
ggml-medium.bin,效能與準確度表現最穩定。 - 內顯或舊型顯卡使用者:
- 日常轉錄建議使用
ggml-small.bin,此為準確度的最低門檻。 - 若需高精確度內容,可選用
ggml-medium.bin並預留較長的處理時間。
- 日常轉錄建議使用
異動歷程
- 初版文件建立。
- 新增推薦連結,引導至新版 Faster-Whisper 解決方案。